Anti-Caching A New Approach to Database Management System Architecture 논문 요약
너무 어려운 논문이다... DDIA 책을 읽다가 '레퍼런스도 챙겨보자!' 해서 읽은 논문인데 역시 논문은 너무 어렵더라. 진이 빠질대로 빠졌지만 지금 정리하지않으면 평생 안할거기 때문에 얼른 정리해본다
https://www.vldb.org/pvldb/vol6/p1942-debrabant.pdf
제목은 Anti-Caching: A New Approach to Database Management System Architecture 이다. Anti Caching 에 대해 다룬다.
우선 Database 와 DBMS 는 다르다. 흔히 얘기하는 MySQL, PostgreSQL, MongoDB 는 전부 DBMS 다. Database 를 관리해주는 시스템이다. DBMS 는 보통 접근 속도를 높이려고 Buffer pool 을 유지하는데 이 오버헤드가 상당하다. Buffer Pool 이 메모리에 있기 때문에 메모리가 가득찰 위험이 항상 있다. 메모리 --> 디스크로 이동시키는 Eviction 정책을 통해 메모리 용량을 관리하는데 이 정책을 유지하는 것도 리소스가 든다. 만약 버퍼풀이 가득찬다면 이 버퍼풀을 유지하는데만도 CPU 1/3 을 사용해야한다. 만약 내가 메모리에 모든 데이터를 올릴 수 있으면 당연히 Buffer pool 을 유지할 이유가 사라진다. 즉 Buffer pool 을 유지하는 데 필요한 오버헤드를 없앨 수 있다.
벤치마크상으로도 '당연히' 메모리만 이용한 DBMS 가 더 좋은 성능을 보인다. 하지만 이건 데이터가 메모리보다 적을 때 이야기고... 만약 데이터가 메모리보다 많아지면 어떡할까? 이 문제를 해결하려고 여러 시도가 있었다.

제일 왼쪽이 Buffer pool 을 사용한 모델이고 두번째가 분산 캐시를 사용하는 방법, 세번째가 이 논문에서 소개하는 Anti Cache 다. Anti Cache 는 '데이터가 메모리에 다 들어갈 수 없을 정도로 크지만 메모리를 Primary Storage 로 사용하겠다.' 는 컨셉이다. 보통 우리는 두 번째 컨셉과 같은 Two-Tier Architecture 를 사용한다. 즉 MySQL 과 같은 디스크 기반 DBMS 앞에 Memcached 같은 분산 캐시를 놔둔다. 이 방법은 두 가지 문제가 있다.
1. DBMS 버퍼풀과 메모리 양쪽에 데이터를 저장하기 때문에 저장공간을 많이 잡아먹는다.
2. 둘 사이의 싱크를 맞추는 로직이 꼭 필요하다.
Anti caching 은 위와 같은 문제도 해결가능하다. 어찌보면 OS 의 가상메모리와 비슷한데, 가상 메모리와 비교해서 두 가지 장점이 있다.
1. Fine grained Eviction
사용하지 않는 Tuple 만 모아서 Eviction 시킬 수 있다. 반면 OS 의 가상메모리는 페이지 중 단 하나의 Tuple 만 자주 접근되더라도 페이지 전체가 계속 메모리에 남아있게된다.
2. Non Blocking Fetches
OS에서 접근하려는 Page 가 메모리에 없으면 Page fault 가 발생한다. 디스크에서 데이터를 읽어와야하는데 이 때 OS 가 트랜잭션을 차단한다. 심지어 몇몇 DBMS 는 모든 트랜잭션의 동작을 중단시킨다. 가상 메모리 페이지가 메모리에 적재되면 다시 동작하는데 이 때 만약 접근하려는 페이지가 다양하다면, 그리고 그 페이지들이 메모리에 없다면 지속적으로 트랜잭션은 멈추게 된다. 예를 들어 Page 1, 3, 5 를 접근해야하는데 이 셋 모두 메모리에 없다면
Page 1 접근 --> Page fault --> 트랜잭션 차단 --> Page 1 메모리 적재 --> 트랜잭션 재개 --> Page 3 접근 --> Page fault --> 트랜잭션 차단 --> Page 3 메모리 적재 --> 트랜잭션 재개 ...
Page 1 접근 --> Page fault --> 트랜잭션 차단 --> Page 1 메모리 적재 --> 트랜잭션 재개 -->
Page 3 접근 --> Page fault --> 트랜잭션 차단 --> Page 3 메모리 적재 --> 트랜잭션 재개 ...이런 식으로 진행된다.
하지만 Anti Caching 은 트랜잭션을 잠시 중단하지만 다른 트랜잭션이 계속 동작할 수 있다. 또, 메모리에 없는 Block 을 접근하면 pre-pass 를 사용해서 이 transaction 안에 얼마나 많은 tuple 이 메모리에 없는지 파악해서 한번에 메모리에 적재한다. 연쇄적인 Page-Fault 를 막을 수 있다. 위와 같은 예시를 들면
Page 1 접근 --> Page fault --> 트랜잭션 중단 && pre-pass 발동 --> Page 1,3,5 메모리 적재
--> 트랜잭션 재개이렇게 된다.
Anti Cache 는 세 가지 컴포넌트로 구성되어있고 각 컴포넌트는 한번에 하나의 Transaction 만 접근할 수 있기 때문에 따로 Latch 가 필요하진 않다.
1. Block Table : 디스크에 상중하는 해시 테이블로서 evicted tuple block 을 가지고 있다.
----------------------------------------
2. Evicted Table : 메모리에 상주하며 evicted tuples: block ids 형태로 되어있다.
3. LRU Chain : 메모리에 상주하며 각 테이블마다 Tuple 로 구성되어있다.

1. Block Table
- Block 의 헤더는 Block ID 와 이 Block 이 생성된 타임스탬프로 이루어져있다. 여기에 모여있는 튜플은 그 크기가 가장 앞에 있고, 데이터는 memory 형태로 직렬화되어있다.
2. Evicted Table
- 디스크 Block 에 쓰인 Tuple 을 기록한다. Tuple 이 Block Table 의 어떤 Block 에 위치하는지 기록한다.
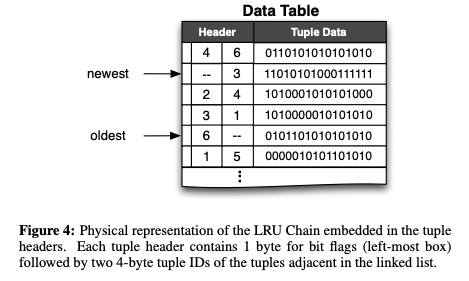
3. LRU Chain
- LRU 순서로 정렬되어있는 양방향 링크드 리스트이다. 만약 아주 자주 접근되는 테이블이 있으면 이 테이블에 evictable 라벨을 붙이지 않는다. 라벨이 붙지않은 테이블은 메모리에 상주한다.
구성 요소까지 봤으니 이제 가장 중요한 Eviction 을 어떻게 하는지에 대해 알아보자

우선 LRU Chain 의 머리 부분에서 Pop 을 해서 이 tuple 을 evicted block buffer 에 복사한다. 그 후 evicted table 에도 이 tuple 을 기록한다. 이로서 이 tuple 이 eviction 된 걸 알 수 있다. 모든 인덱스도 tuple 이 evicted table 에 기록된 위치를 가리키도록 한다. Evicted table 에 있는 tuple 은 header 부분에 evicted flag 가 있어서 이 tuple 이 eviction 된 걸 나타낸다. Block 이 가득찰 때까지 이 과정을 반복한다. 그 후 이 Block 을 디스크에 기록한다.
이 과정은 쓰레드 하나만 동작하기 때문에 index 와 tuple 의 위치가 변경되지만 충돌은 발생하지 않고 만약 하드웨어 장애가 난다하더라도 충분히 복구할 수 있다.
Block 조회 과정
(1) disk 에서 block 을 읽어오기위해 별도 쓰레드에서 non-blocking read 한다. 이렇게 읽어온 데이터를 query 에서 접근할 수 없는 별도 버퍼에 보관한다. 이 때 다른 트랜잭션에서 같은 데이터를 접근하더라도 마치 메모리에 없는 것처럼 처리한다. DIsk 에서 Block을 가져온다는 건 트랜잭션이 일시중단되었다는 걸 의미한다.
(2) 데이터를 읽어온 후엔 transaction 을 rescheduled 하는데 이 과정 직전에 "Stop-and-Copy" 과정을 거친다. 해당 파티션에서 동작중인 모든 transaction 은 중단된다. 아까 buffer 에 있던 tuple 이 staging buffer 에서 regular table storage 로 병합된다. Evicted Table 에서 이 tuple 들을 삭제하고 테이블 인덱스가 이들을 가리키도록 한다.
병합 방법은 아래 두 가지가 있다.
Block merging
block 전체를 in memory 테이블에 병합한다 이 때 이 block 에서 조회된 tuple, 즉 요청된 Tuple 은 LRU Chain 의 끝에 넣고 그렇지 않은 tuple 은 LRU Chain 의 헤더에 넣어서 다음에 이 tuple 들이 먼저 eviction 되도록 한다. 예상하다시피 이건 필요한 tuple 이 하나인 경우에도 block 의 모든 tuple 을 병합해야하는 단점이 있다.
Tuple Merging
Evicted Table 에 Tuple 에 대한 offset 이 있으니까 필요한 Tuple 만 Offset 을 활용해서 조회한다. 이 Tuple 을 In-Memory 에 Merge 하고 Block 의 나머지 튜플은 버린다. 그 후 Evicted Table 에서 Merge 된 tuple 에 대한 정보를 지운다. Evicted Table 에서만 정보를 제거했기 때문에 실제로 데이터는 메모리와 디스크, 양쪽에 있지만 접근은 In-Memory 쪽만 가능하다. 시간이 지날수록 Block 의 구멍이 커져서 lazy block compaction algorithm 을 추가했다. block 을 읽을 때 threshold 보다 구멍 크기가 크면 전체 block 을 머지한다.
Snapshots & Recovery
스냅샷을 뜨는 동안은 eviction 을 하지 않는다.
snapshot 용량을 줄이기위해 delta snapshots 을 한다. DBMS 는 단지 이전 snapshot 으로부터, 추가되거나 제거된 Block Table만 체크한다.
Future Work
Larger-than-Memory Queries
Anti Caching 은 메모리보다 큰 DB 를 다룰 수 있게 해준다. 만약 엄청나게 많은 데이터를 조회해야할 땐 쓰기 작업과 어떻게 병행해야할까?
1. 전통적인 DB 처럼 쓰기 작업에 대해 Table Level Lock 을 걸고 쓰기 작업이 끝난 후 읽기를 수행한다.
2. historical mode 로 운영한다. 트랜잭션을 받을 때 타임스탬프값도 함께 받아서 이 시간 이후의 tuple 만 읽는다. 따라서 쓰기 작업의 overwrite 는 허용하지않는다. 단, before and after 이미지를 모두 유지해야한다.
3. dirty read 를 허용한다. 즉 읽기도중 변경된 tuple 도 그냥 다 읽는다.