이번 글에서는 데이터를 저장할 몽고디비를 설치하고, 실제로 데이터를 집계하는 파이썬 파일을 작성해보겠습니다.
------------------------------------------------------------------------------------------------------
대다수의 분산 시스템은 자바 언어로 구현되어있어서 JDK라는 게 있어야합니다.
java -version 명령어를 통해 자바 버전을 확인할 수 있습니다.
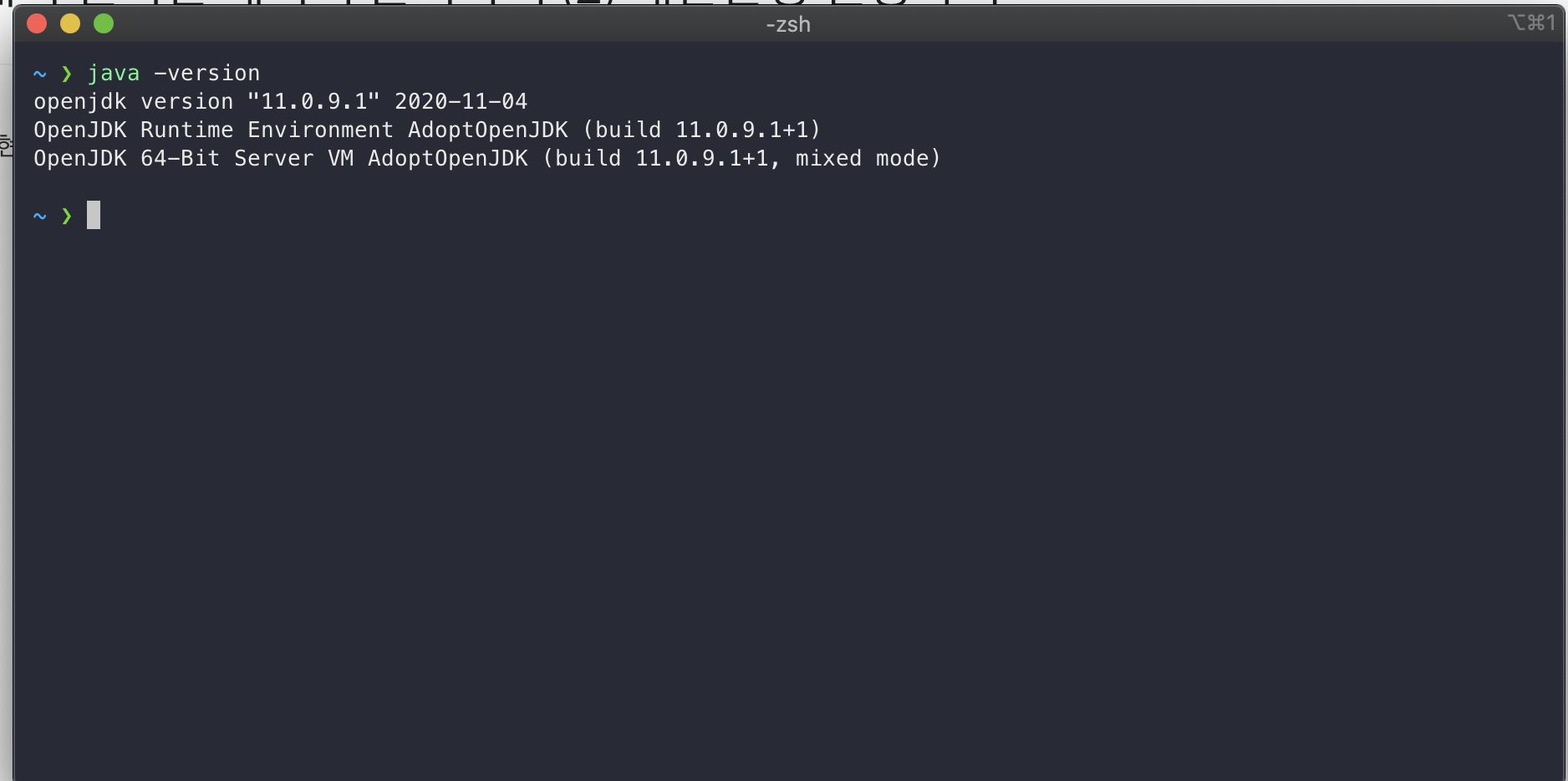
아무것도 안뜨거나 'Unknown Command', 'Command not found' 등의 에러가 뜬다면 자바가 설치되어있지 않은 상태입니다.
자바가 안 깔려있으면 깔아주세요. 구글에 '자바 설치' 등으로 검색하면 무수히 많은 글이 나오니 설치방법은 생략하겠습니다. (자동으로 설치화면으로 넘어가기도 합니다) 자바는 무조건 1.8버전 이후의 것으로 깔아주세요!
파이썬도 필요합니다.
python --version으로 버전을 확인할 수 있는데 만약 설치되어있지않다면 설치해주세요.
제가 튜토리얼을 진행할 환경은 파이썬 2.7 입니다.
아마 새로 파이썬을 배우고 계신 분들은 3.x 가 설치되어 있을텐데 저희가 나중에 사용할 'Apache Spark'가 3.x 버전에서 동작하지 않는 이슈때문에 2.7버전을 권장드리지만 현재는 버전 문제가 해결됐다는 얘기도 있어서 3.x로 진행하셔도 문제 없을 듯 합니다.

그 다음은 데이터베이스입니다. 저희는 MongoDB를 사용할 예정입니다.

설치가 안되어있네요.
www.mongodb.com/try/download/community
MongoDB Community Download
Download the Community version of MongoDB's non-relational database server from MongoDB's download center.
www.mongodb.com
윈도우 사용자는 본인의 운영체제에 맞게 몽고디비를 설치해줍시다.
$ brew tap mongodb/brew
$ brew install mongodb-community맥 사용자는 이렇게 설치하시면 됩니다.
그 후에
$ brew services start mongodb-community이 명령어를 통해 mongodb-comuunity를 실행시켜줍니다.
윈도우를 사용하시는 분도 비슷하게 실행시키시면 될텐데,
구글에 '윈도우 몽고디비' 를 키워드로 검색하시면 많은 글이 나오니까 참고하시면 될 것 같습니다.
(참고 : m.blog.naver.com/wideeyed/221815886721)
[MongoDB] 몽고DB 설치 및 테스트 on Windows
원도우에 몽고DB를 설치하는 방법에 대해 알아보겠습니다.MongoDB란? Document-based 또는 Docume...
blog.naver.com
몽고디비를 정상적으로 실행하셨다면 파이썬 파일을 작성해서 실제로 트위터의 데이터를 수집해봅시다.
그 전에 파이썬으로 설치해야 할 것이 있습니다.
$ pip2 install pymongo requests_oauthlib tqdm request
위 명령어를 통해 필요한 라이브러리를 설치해줍시다.
그 후에 파이썬 파일을 작성해줍시다('github.com/twitterdev/Twitter-API-v2-sample-code/blob/master/Sampled-Stream/sampled-stream.py') 아래 코드를 복붙하시면 되는데, 아래쪽에 토큰은, 저번에 발급받았던 Bearer Token을 넣으시면 됩니다.
#-*-coding utf-8-*-
import requests
import os
import json
# To set your environment variables in your terminal run the following line:
# export 'BEARER_TOKEN'='<your_bearer_token>'
def create_url():
return "https://api.twitter.com/2/tweets/sample/stream"
def create_headers(bearer_token):
headers = {"Authorization": "Bearer {}".format(bearer_token)}
return headers
def connect_to_endpoint(url, headers):
response = requests.request("GET", url, headers=headers, stream=True)
print(response.status_code)
for response_line in response.iter_lines():
if response_line:
json_response = json.loads(response_line)
print(json.dumps(json_response, indent=4, sort_keys=True))
if response.status_code != 200:
raise Exception(
"Request returned an error: {} {}".format(
response.status_code, response.text
)
)
def main():
bearer_token = 토큰토큰토큰토큰아까그BearerToken
url = create_url()
headers = create_headers(bearer_token)
timeout = 0
while True:
connect_to_endpoint(url, headers)
timeout += 1
if __name__ == "__main__":
main()그리고 파일을 실행하면 이런 결과물을 볼 수 있습니다. Twitter API는 기본적으로 id와 text만 추출하는데 원한다면 다른 필드도 추가할 수 있습니다.

GET /2/tweets/sample/stream
By using Twitter’s services you agree to our Cookies Use. We use cookies for purposes including analytics, personalisation, and ads.
developer.twitter.com
어떤 필드의 데이터를 들고올 수 있는지는 이 링크를 참고하시면 됩니다. 처음하시는 분은 다소 어려울 수도 있으니, 댓글 달아주세요. 저를 아시는 분은 갠톡주세요.
일단은 샘플 데이터를 잘 받아왔습니다.
ID와 TEXT만 받아오는 게 심심해서 geo와 created_at(생성날짜)도 추가로 받아오기로했습니다. 아래와 같이 파이썬 파일 내에 create_url함수의 url을 수정하면 되고, 원하는 필드는 계속 반점을 붙여가면서 추가할 수 있습니다. url뒤에 geo와 created_at가 추가된 걸 확인하실 수 있습니다.
def create_url():
return "https://api.twitter.com/2/tweets/sample/stream?tweet.fields=geo,created_at"
잘 받아오네요. 저희는 빅데이터 분석을 할거니까 이걸 mongodb에 저장하겠습니다.
pymongo를 이용해서 몽고디비랑 연결하겠습니다.
아래 코드를 복붙하실 때 토큰바꿔끼우시는 걸 잊으시면 안됩니다.
# -*- coding: utf-8 -*-
import requests
import os
import json
from pymongo import MongoClient
# To set your environment variables in your terminal run the following line:
# export 'BEARER_TOKEN'='<your_bearer_token>'
############################# 추가된 부분 ###########################
client = MongoClient('localhost', 27017) # Mongodb에 연결합니다.
db = client.twitter # twitter라는 데이터베이스 만듭니다.
##################################################
def create_url():
return "https://api.twitter.com/2/tweets/sample/stream?tweet.fields=geo,created_at"
def create_headers(bearer_token):
headers = {"Authorization": "Bearer {}".format(bearer_token)}
return headers
def connect_to_endpoint(url, headers):
response = requests.request("GET", url, headers=headers, stream=True)
print(response.status_code)
for response_line in response.iter_lines():
if response_line:
json_response = json.loads(response_line)
################## 바뀐 부분 ####################
db.data.insert_one(json_response)
#########################################
if response.status_code != 200:
raise Exception(
"Request returned an error: {} {}".format(
response.status_code, response.text
)
)
def main():
bearer_token = 토큰토큰토큰토큰아까그BearerToken
url = create_url()
headers = create_headers(bearer_token)
timeout = 0
while True:
connect_to_endpoint(url, headers)
timeout += 1
if __name__ == "__main__":
main()
그러면 데이터가 잘 저장되는 걸 확인할 수 있습니다. 직접 확인하고 싶으신 분은 몽고디비에 접속하시면 되는데 터미널환경이 익숙하지 않은 분은 MongoDB Compass를 이용하시는 걸 권장드립니다. 사실, 익숙하신 분도 그냥 compass 쓰시는게 편하실수도 있습니다. www.mongodb.com/try/download/compass 여기서 설치하시면 됩니다. compass에 대한 것도 구글링하면 자료가 많으니 생략하겠습니다.
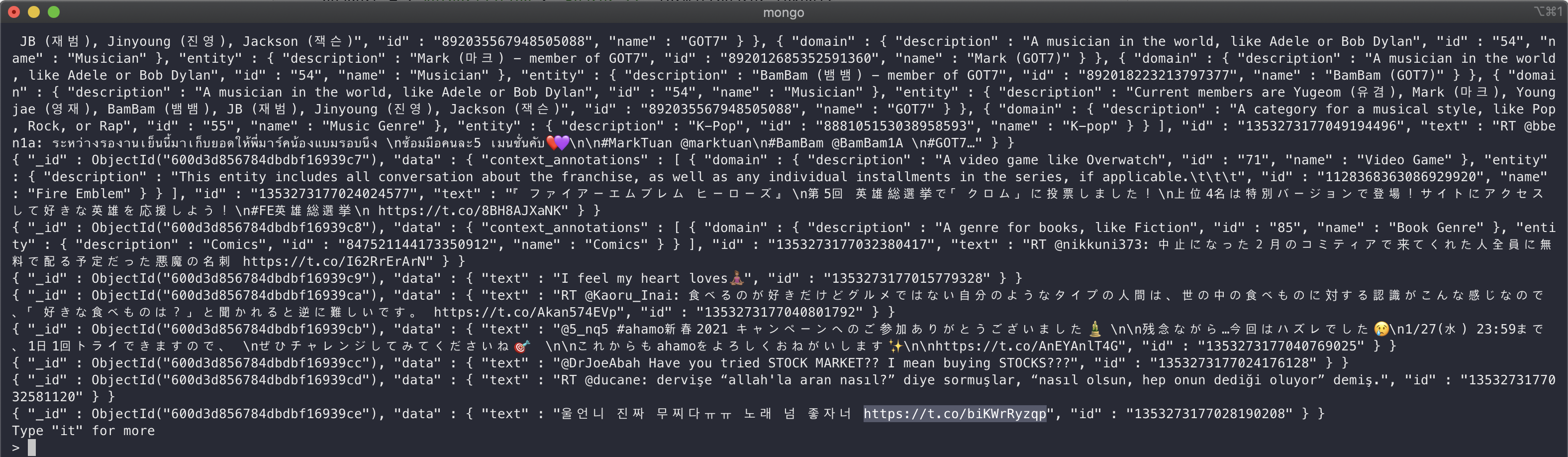
저장된 트위터 중 하나에 들어가보면

잘 되네요
다음에 뵐게요~
다음에는 이 자료들을 이용해서 시각화를 해보겠습니다.
'데이터분석_플랫폼' 카테고리의 다른 글
| twitter API를 이용해서 실시간 데이터 분석하기 (1) 트위터 개발자계정 신청 (0) | 2021.01.24 |
|---|
